Source Compression with Bounded DNN
中文题目
Iot 设备,边缘计算机视觉中,限制 DNN 预测损失的,源压缩方法
摘要
我们通过设计一种连续可调的方法来利用本地和远程资源来优化深度学习模型的性能。Clio 提出了一种新颖的方法,以适应无线动态的改进方式在物联网设备和云之间拆分机器学习模型。
1.introduction
现状
一些常开传感器更加节能,可以通过电池供电,如相机、IMU、麦克风。
这些趋势导致了一个新兴的市场,用于支持低功耗连续分析的相关计算元素。最近公布的几种神经加速器芯片组,如 Green Waves GAP8、EtaCompute Tensai 和 Syntiant NDP 的功耗小于 100mW,从而使我们可以设想配备神经加速器的 Mote 类设备。
问题
尽管如此,低功耗加速器上的可用资源与高效执行先进深度学习模型所需的资源之间仍然存在着巨大的差距。低功耗加速器的资源比这些嵌入式处理器 (例如 GAP8 有 1 个 GFlops 的卷积加速器, Raspberry Pi 有 24 个 GFlops , iPhone X 有 350 个 GFlops) 少 2 ~ 3 个数量级。即使是最先进的深度学习模型的最小版本,如 ResNet - 18、VGG - 16 和 MobileNetV2,也需要 5 - 20 倍的计算和内存占用。
模型压缩的一种替代方法是利用无线通信将数据传输到云端进行处理。与其对模型进行压缩,不如使用有损压缩技术对原始数据进行压缩,传输到云端,利用云资源进行预测。然而,挑战在于低功耗无线电的带宽有限,并且由于低功率传输,对于环境变化和波动十分敏感。同样压缩图片可能影响效果。
本文解决的核心问题
我们能否同时利用模型压缩 (其中,模型被压缩以拟合本地计算资源) 和数据压缩 (其中数据被压缩以适应狭窄的无线链路) 来最大化推理质量?许多研究在探索划分深度学习模型,一部分边缘云一部分设备。然而,对于大多数先进的模型,来自各个层的中间结果往往相当大,并且使用低带宽的物联网无线电传输效率低下。**由于在物联网设备上给定计算和内存约束,只有深度学习模型的早期层作为分区点是可行的。**在移动环境中,现有技术需要针对特定的带宽设置进行仔细的训练,并且不能根据带宽的动态变化进行动态调整。
我们的方法
CLIO 方法:在这项工作中,我们试图解决这些问题,并回答如何同时利用超低计算和通信组件来提高推理精度这一重要的基本问题。我们提出了一种新颖的模型编译框架 Clio1。该框架为深度学习模型在低功耗物联网设备和云之间进行划分提供了一个连续的选项,同时在资源有限且动态变化的情况下优雅地降低了性能。Clio将改进传输与模型压缩和自适应划分相结合,以响应无线动态。
Clio 的一个关键好处是,它允许使用模型编译技术。Clio 将原始模型中需要编译的部分限制在边缘设备上进行编译(先编译、再传输),这样可以充分利用可用带宽进行云端计算,降低了所需的压缩程度。
我们给出了 clio 在计算架构、无线电架构和数据集中的实验评估。clio 可以编译 MobileNet 和 ResNet-18 等先进模型,减少端到端的延迟和功率消耗的同时,准确率没有明显下降。与现有的数据压缩、模型压缩和分区执行相比,本文由明显优势。
我的总结
由于边缘设备执行深度学习模型过于耗电、耗算力,因此考虑压缩模型,还是过于耗电、耗算力,因此考虑传输到边缘云(分区执行),但是传输受带宽限制,因此考虑压缩数据(如果需要传输模型,还需要压缩模型)。
本文就是把三者结合起来。
2.CLIO 的进一步阐述
问题关键
从无线传输的角度来看,主要的挑战是处理不确定的无线条件。物联网无线电以高占空比的方式运行,以节省电能。然而,这是以唤醒时不知道可用带宽为代价的,因为信道可能自上一个唤醒期以来已经发生了变化。此外,针对不同的可用带宽预训练和部署大量不同的模型并不实际。最后,由于在睡眠期间失去同步,当事件发生时有额外的连接延迟开始传输数据。
从计算的角度来看,关键的挑战是缺乏足够的本地资源。虽然低功耗加速器具有快速执行深度学习模型的架构模块,但它们仍然受到计算能力、内存大小和最大工作频率的限制。现有的深度学习模型需要比现有模型多两到三个数量级的计算资源。
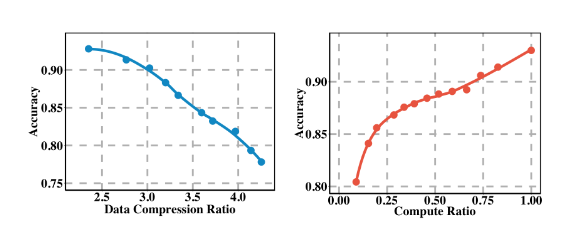
左图,数据压缩与准确率,右图,模型压缩与准确率。模型压缩比例为原来 25% 时,效果下降显著。(在 CIFAR - 10 图像上执行 MobileNetV2 模型)
数据压缩与模型压缩的比较
数据压缩:通过传输有损版本的数据进行远程执行来压缩数据量
模型压缩:我们压缩较大的模型以在期望的延迟界限内本地执行
资源严重受限的时候,两种方法准确性都很低。
用专门针对资源受限 MCU 设计的手工模型来代替模型压缩并不能解决问题。例如,CMSIS - NN 是专门针对 ARM STM32F7 优化的卷积神经网络[ 27 ],但该模型在 CIFAR - 10 数据集上的准确率只有 80 % 左右,而全 MobileNetV2 模型的准确率为 93 %。
模型分割
另一种流行的方法是边云模型划分,以利用远程和本地计算资源来优化性能。即一部分边缘云,一部分本地。现有的划分模型不能直接解决带宽不确定性问题。同时存储大量针对不同带宽优化的模型不可行。
Clio 的实现
Clio 的核心是一种物联网 - 云联合优化技术,用于按顺序递进地传输分区模型的中间结果以应对带宽变化。除了引入一种新的技术来增强分区模型的运行,Clio 还提出了一个集成的解决方案,将模型压缩、模型分区和改进传输的各个部分结合起来,在动态带宽设置下创建一个用于分区执行的集成系统。
3 CLIO 设计
3.1clio 的整体运行
Clio 运行时对短期和长期带宽动态的响应不同。需要快速适应带宽的情况有两种。第一种是在信道条件未知的情况下,节点在深睡眠 (即在占空比操作期间) 中,工作后唤醒。第二种是当链路带宽因移动性而发生不可预测的变化时。Clio 通过循序渐进的方式来适应这些条件。
当带宽变化持续较长时间时,Clio 对分区点进行自适应,使其能够在当前条件下运行在最佳分区。比如,模型在第五层被划分可以适应 250kbps 到 1mbps 之间的带宽,如果带宽下降到 100kbps,那么需要切换到不同的分区点,以进一步缩小中间结果的大小,更好的应对较低的可用带宽。
3.2 改进切片
前言
一个深度学习模型 M 可以由层 V 和有向边 E 组成的 G=(V,E) 表示,G 是有向无环图。图的分割点是图 G 的一个割,C 包含于 E,他将模型 M 分成两部分。
为了简化这个优化问题,我们将切割限制在模型中连续两层之间。只有第 k 层和第 k+1 层之间可以割。我们只是将模型分布在边缘设备和云端,精度不变。
学习过程的有序隐藏表示
clio 持续的适应以递进方式传递的中间活动层,在给定的带宽限制下实现效果最大化。我们通过一个训练过程实现上述内容,该过程训练了一个单一的模型,该模型可以不断地适应从边缘设备上的第 k 层到云上第 k+1 层的中间数据的大小。对于每个中间数据的大小,我们为云学习一个单独的模型。这些模型从对应大小的 k 层接收数据并解码传输的表示,产生最终的输出。
设 O_k = fθ ( x ) 是一个函数,表示模型运行到第 k 层的输出,同时第 k 层由 w_k 个单元。现在定义切片函数 O_1:𝑖 = slice(𝑖, O),表示把 O 从 i 切到 i,只取 O 的前 i 个通道。𝑦 = 𝑔_𝜙𝑖 (O_1:𝑖,𝑘 ) 是一个函数,代表 M 只接受传来的第 k 层的前 i 个通道值作为输入,产生网络的输出。注意到该函数对于 i 的每个值都有单独的一组参数。
该模型在给定时延约束和可用带宽的情况下,通过无线链路从第 k 层到第 k + 1 层传输尽可能多的隐藏单元。则模型最终的预测输出为𝑦 = 𝑔_𝜙𝑖 (slice(𝑖, 𝑓_𝜃 (x)))。
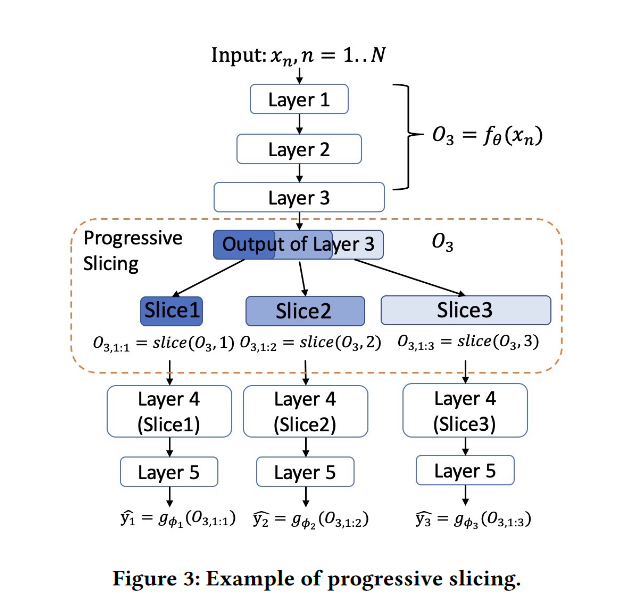
该方法成功的关键是使用一个损失函数来训练模型,该损失函数考虑了可用带宽上的分布,从而考虑了可传输的表示大小。令π i 表示有足够带宽可用来发送 slice(i,f_θ(x)) 的概率。给定一个数据集 D = {(x_𝑛, 𝑦_𝑛), 𝑛 = 1 : 𝑁 },以及一个预测的损失函数ℓ (𝑦, 𝑦′),我们基于中间层 slice(𝑖, 𝑓_𝜃 (x)) 定义了损失为 L_𝑖 (D; 𝜃, 𝜙_𝑖 )。我们优化的总体损失是 L_𝑖 (D; 𝜃, 𝜙_𝑖 ) 的期望值,通过我们可以发送 slice(𝑖, 𝑓_𝜃 (x)) 的概率𝜋_𝑖,我们可以取得这个期望值。该模型因此学习到了有序隐藏表示的参数。对于给定的大小为𝜋的表示上的分布的渐进切片操作,这些参数可以最小化期望的误差。具体如下:
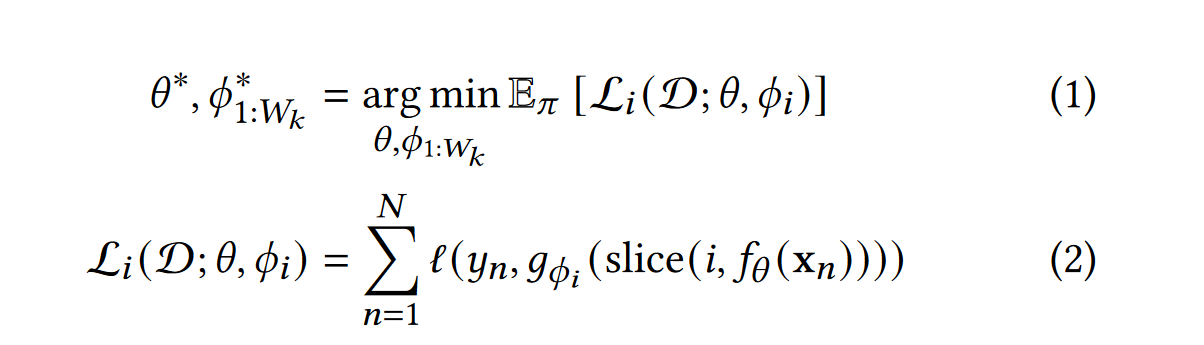
举例说明
我的理解
第二个式子说的是损失函数 L,表示对于第 1 层到第 N 层求和;第 n 层的输出 yn,与第 n 层经过切片后的输出𝑔𝜙𝑖 (slice(𝑖, 𝑓𝜃 (x𝑛))) 的差ℓ (𝑦𝑛, 𝑔𝜙𝑖 (slice(𝑖, 𝑓𝜃 (x𝑛))))。
第一个式子说的是,在概率分布为𝜋的情况下最小化这个损失。𝜋_𝑖代表的是我们能发送出切片 1:i 的数据的概率(很明显,i 取得越大,我们能发出切片 1:i 的概率𝜋_𝑖就越小;𝜋_𝑖还与分割层 k 有关,k 越复杂,𝜋_𝑖越小;𝜋_𝑖取决于网络的带宽,因为 k 与 i 为内因,带宽为外因,带宽越窄,𝜋_𝑖越小)
这个模型已知的参数是:带宽
这个模型搜索的参数是:k 代表从那一层开始切割,i 代表切割多少。
3.3 自适应划分
我们已经假设知道了最佳的划分点。虽然改进切片确实提供了处理数据传输大小变化的能力,但单个分区点可能无法在带宽条件下提供足够的动态范围。(无法适应极端的带宽)
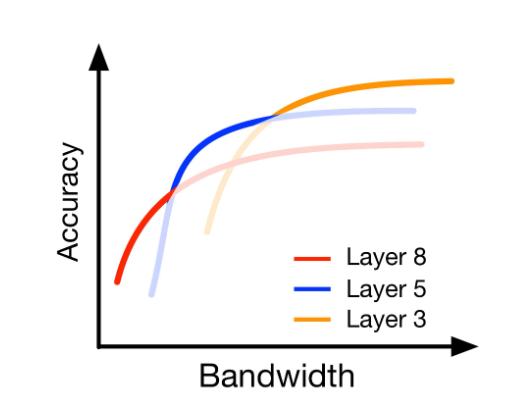
对于每个分割点,改进传输是一条曲线,提供不同的精度 - 带宽权衡。因此,给定特定带宽下的最佳工作点是在该带宽下具有最高精度的<划分,切片>
因此我们就构建了类似上图的性能图,这些曲线可以使用平台级的基准测试来计算。构建这样的曲线可能需要大量训练时间,在 3.4 我们讨论了如何优化
结合模型压缩
有几种方法用于嵌入式设备上的模型压缩,包括权重量化、权重稀疏化、紧凑滤波器等。我们在计算的不同阶段应用这些模型压缩方法,剪枝发生在改进切片之前,而权重量化和稀疏化发生在改进切片模型训练之后。我们的实现集成了 AutoML(权重量化和稀疏化) 和 Meta-pruning(剪枝)
3.4 减少训练时间
𝐶 (L_1:k) 代表模型 M 在 k 被划分的情况下,1-k 层的训练代价。早期的层 L1:k 将被共享 (因为它们不受切片的影响),而层 Lk + 1:K 的集合对于每个切片将是不同的。因此模型的计算消耗为𝐶 (M) = 𝐶 (L1:k) + #slices ×𝐶 (Lk+1:K)。因此训练代价受到两个参数的影响 - - 切片数和划分点数
减少改进切片的训练时间
我们采用了 2 个优化:
1.我们设置一些π_i 为 0,因为我们不考虑所有的 i,只考虑一个给定整数的倍数或者幂,这样 i 的数量大大减少。
2.我们将参数从 k+2 层开始绑定。这样我们只在云上的第一层扩展所需要的参数。就是切片之后的层里面,有很大一部分是可以重复使用的。大切片输入下一层后,下一层输出的结果实际上包括了小切片的结果。
减少潜在的分区点
我们用带宽覆盖启发式方法去选取少数几个分区点,减少训练时间。对于每一个划分层,都可以通过改变切片大小提供给带宽的一个可变化范围。因此,我们使用贪心算法只选择能够扩展带宽可变化范围的层。具体如下。
为了估计一个层上的改进切片可以支持多少带宽范围,我们首先需要知道有多少时间可用来通信。令 Ciot ( · ) 和 Ccloud ( · ) 分别表示物联网设备和云端的计算延迟。这些函数可以通过一次性的离线分析为每一层估计所取的值。
对于在第 K 层划分的模型,计算总延迟为𝐶𝑖𝑜𝑡 (L1:𝑘 ) + 𝐶𝑐𝑙𝑜𝑢𝑑 (L𝑘+1:𝐾 ) 为𝜖^𝐶_𝑘,用于计算的总能量为𝐶𝑖𝑜𝑡 (L1:𝑘 ) 为𝜖^𝐶_𝑘。对于第 k 层,给定一个端到端延迟目标或总能耗𝜖_𝑡𝑎𝑟𝑔𝑒𝑡,我们只能使用𝜖_𝑡𝑎𝑟𝑔𝑒𝑡 −𝜖^𝐶_𝑘进行通信来传输中间结果。Ok 表示从第 k 层逐级分片的中间结果的不同大小,R ( · ) 表示根据目标延迟将传输大小映射回所需带宽的函数,我们可以计算出在第 k 层改进切片可以动态调整的带宽范围 B_k
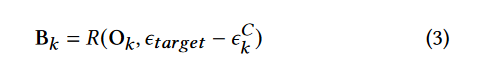
给定这个范围,我们只选择最有前景的分区作为覆盖感兴趣的带宽范围 (例如蓝牙从 50kbps 到 2Mbps) 的最小区间集。这是一个简单的区间覆盖问题,可以使用贪婪算法来解决.
我的理解
给定一个传输的最大时间,给定从第 k 层切片时结果的不同大小,就可以求得带宽的变化范围,一个切片大小对应一个带宽。因此有些层 k 无论你是否考虑从这一层切片,都不会影响带宽的可变化范围,这些层无需考虑。
这实际上产生一个问题,带宽不能变,但是有些层 k 可能占用较大带宽可以实现很好的效果,但是由于这个带宽之前出现过,因此将他排除了。
4.实施
我们为几个最先进的神经网络模型和物联网加速器和处理器实例化 Clio,并在不同的数据集上进行评估。具体实现过程如下。
4.1 将 Clio 编译为模型
我们将 Clio 应用于几个不同的神经网络模型,包括 MobileNetV2、VGG 和 ResNet。我们在任意层或块(ResNet 中的残差块或 MobileNetV2 中的瓶颈结构)之后进行划分,不在每个块结构内部进行划分。
跨连接
MobileNetV2 使用跳跃连接连接卷积块的开始和结束;通过这样做,网络有机会访问卷积块中未被修改的早期激活。跳跃连接通常存在于输入和输出大小相同的情况下。由于 Clio 在训练过程中逐步将中间结果切割成不同的大小,因此我们将跳跃连接由加法操作改为 1 × 1 卷积操作,从而可以处理不同大小的输入和输出。
模型压缩
Clio 可以与最先进的压缩技术结合。在实现中,我们将 Auto ML [ 17 ] 和 Meta Pruning [ 33 ] 应用于 Mobile Net V2。我们还使用宽度乘子作为基线来压缩 MobileNetV2 模型。
减少训练时间
我们为早期分区点选择每 2 层,为后期分区点选择每 4 层进行改进切片。例如,当我们在实现中使用 300ms 的目标延迟时,MobileNetV2 的第 3 层、第 5 层和第 8 层之后的分区点是根据我们的启发式选择的,因为它们可以将我们的带宽范围分别扩展到 195kbps、175kbps 和 98kbps。
4.2 将模型编译到 Iot 设备
Clio 将模型编译为两个子模型 - - 在物联网设备上本地执行的子模型和在云服务器上远程执行的子模型。我们来看两个物联网处理器。GAP 8 是一款超低功耗的神经加速器,其硬件卷积引擎 ( Hardware Convolutional Engine,HWCE ) 可以加速卷积运算。STM32F7 是目前流行的基于 ARM7 的物联网处理器,没有卷积加速器。我们对 MobileNetV2 在 GAP8 加速器上的评估是基于一个完整的端到端实现 (下面进行更详细的说明)。对于 ARM7 处理器,我们根据在 GAP8 上的实现来估计计算成本,但使用 ARM7 的频率和每条指令的 Risc - V 周期。在 ARM7 中,乘法、加法、比较等运算在 MCU 中并行执行。
GAP8 实施
GAP8 平台只对浅层模型和无线通讯有基本的支持,我们同时使用了更大的模型以及物联网和云模型的集成。我们实现了必要的驱动程序并对其进行优化,以实现 BLE 上的连续运行。我们还编写了软件,将模型从 PyTorch / TFLite 中取出,拆分/加载到 GAP8 中,处理格式的变化,并对其进行优化,使其适合内存使用。
我们使用 TFLite [ 53 ] 文件在 GAP8 上进行模型部署。在将模型转换为 TFLite 文件时,融合了批量归一化等部分操作进行部署。由于 GAP8 只支持固定小数点算术运算,因此在量化过程中,所有的权重和输入都被转换为 8 位 Q 格式的固定小数点数字。同时,中间结果也作为 8 位固定小数点数字进行存储和传输。
MobileNetV2 中的卷积有两种 - - 第一种是基本卷积,第二种是扩展卷积,扩展卷积又包括三个基本卷积 - - 扩展卷积、深度卷积和投影卷积。GAP8 虽然有硬件卷积引擎来加速卷积运算,但由于硬件设计的原因,有些运算并不支持,而是在计算核上并行执行。此外,ReLU6 和 padding 等操作被融合并在计算核心上并行执行。
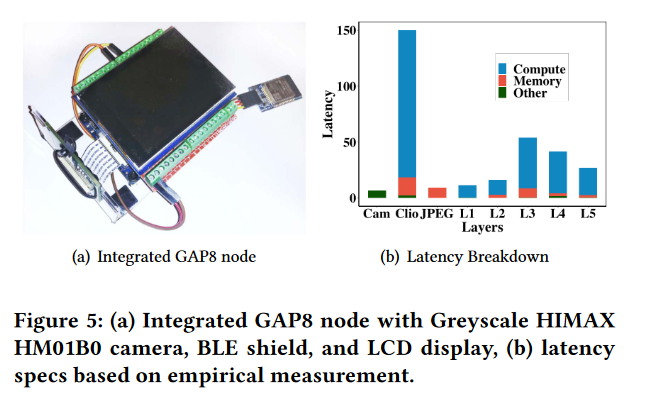
在硬件方面,将 GAP8 板卡与 HIMAX 摄像头、液晶屏以及通过 UART 接口 (如图 5 所示) 连接的无线电屏蔽罩集成在一起。集成板卡捕获一张相机上的图像,在液晶屏上显示,执行模型的早期层,然后通过无线电传输中间结果。
云执行
在云端执行比在物联网设备上执行快得多。对于我们的基准测试,使用至强 4116 2.10 GHz,32 GB DDR4 2400 MHz 和 GTX 1080 Ti GPU。
实时操作演示
我们对以上几部分进行了集成,以支持持续的带电作业。我们制作了一个完整的视频演示系统 (见代码[ 2 ] ) - - 为了制作演示系统,我们必须重新训练和优化来自 GAP8 板的 HIMAX 相机的灰度格式的模型,这不同于我们用于结果的 ImageNet / CIFAR - 10 数据。
在 Gap8 上对 Mobilenetv2 进行测试
我们对 GAP8 进行了分析,以获得不同计算块的延迟和能量基准。
对于延迟分析,我们使用硬件计数器来评估计算、内存复制和其他操作的总周期。我们通过划分 GAP8 时钟频率设置将总周期转换为延迟。图 5 显示了我们的 GAP8 实现 MobileNetV2 早期层执行所消耗的延迟分解。根据延迟分解,我们估计 GAP8 在执行 MobileNetV2 时的等效计算能力约为 525 MMAC / s
对于无线,我们发现从 GAP8 到 BLE 屏蔽层传输数据的最大速度是 250kbps (由于 UART 速度的限制)。我们在评估延迟和能量时使用这些数字
5 评估
在评估 Clio 对抗这些方法之前,我们首先描述了我们使用的数据集和我们对比的方案。
5.1 数据集
CIFAR-10 和 ImageNet。所以我们创建了一个较小的数据集 ImageNet - 20,其中随机设置了 20 个类,并将其用于我们的评估。
5.2 比较
我们在这个评估中对几种方法进行了比较。
数据压缩
在数据压缩方面,我们将 Clio 与 JPEG 压缩后的原始数据传输到云端进行远程处理进行比较。我们使用了目前最先进的基于 JPEG 的编码器 DeepN - JPEG [ 32 ],该编码器专为深度学习工作负载而设计,因此在深度学习任务中的性能优于传统的 JPEG。
我们针对 JPEG 的两个版本进行评估:1.基线 JPEG,其中图像被压缩到期望的质量和系数顺序传输。2.改进 JPEG。在改进的更高细节的不同传递中,压缩系数也不同。
模型比较
在模型压缩方面,我们对比了几种先进的局部压缩选项:meta-pruning、adapting the width-multiplier、AutoML
划分
我们还与现有的模型划分方法进行了比较:Neurosurgeon、JALAD、2-step Pruning
5.3 改进切片 vs 改进 JPEG
现在比较改进切片和改进 jpeg。
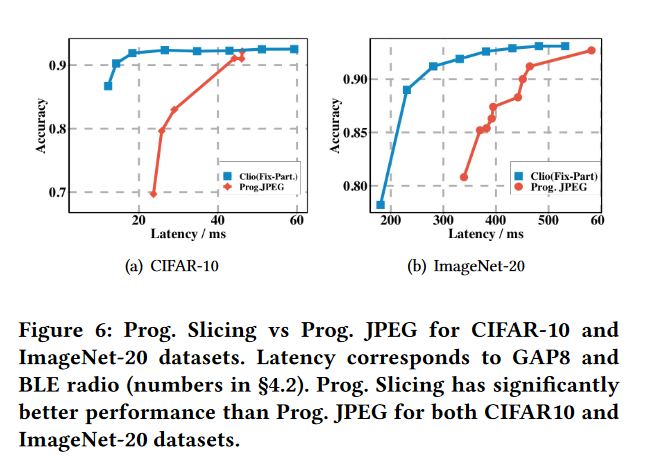
我们首先看在 JPEG 压缩数据上与远程计算相比的性能优势。图 6 展示了两个数据集 ( CIFAR - 10 和 ImageNet - 20) 和一个工作在 250kbps 的 BLE Radio 的延迟结果。我们发现具有固定分割点的 Clio 明显优于 Progressive JPEG,特别是在低延迟时。当度量指标为能量而不是延迟时,结果几乎完全一致,因此我们不展示这些结果。
5.4 Clio vs 模型压缩
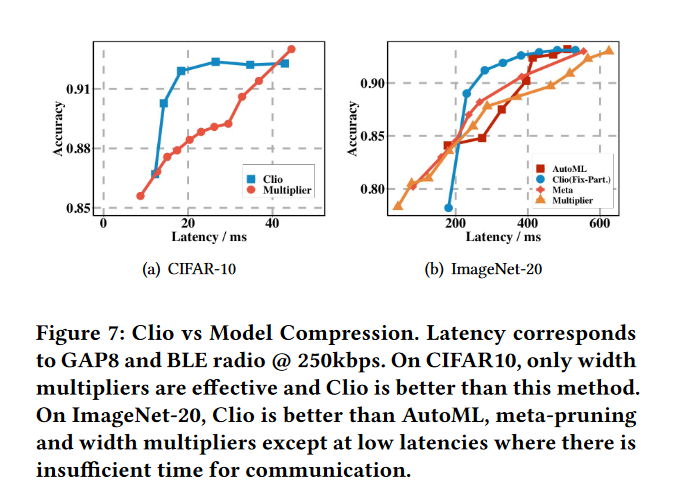
我们现在评估 Clio 相对于那些试图将整个 MobileNetV2 模型压缩到 GAP8 的资源约束中的模型压缩方法的好处。
5.5 比较本地、远程和 Clio
我们现在更全面地看待这三种方法,以尝试理解它们各自最有效的工作机制。然而,由于不同的因素影响不同的方法 - - 局部执行依赖于计算/内存资源和计算效率,因此设计空间很大;远程执行依赖于可用带宽和无线效率;和 Clio 取决于上述所有因素。我们不是单独查看每个设计参数,而是通过几个示例体系结构和 MobileNetV2 模型来说明总体趋势和权衡。
我们看每种方法与 Clio 对应 90 % 准确率 (其他精度的选择类似) 的性能比。对于每种方法,我们评估其性能与 Clio 的比率,延迟或能量比率大于 1 意味着该方法与 Clio 相比具有更高的延迟/能量。

我的理解
横竖坐标都表示设备,坐标系的一个点表示此时选择横竖坐标对应的设备。红色区域是 clio 最好,左面蓝色区域是远程计算好(压缩图片),右面蓝色区域是本地计算好(压缩模型)。
5.6 适应分区点的好处
我们考虑两个版本的 Clio - - 一个固定的分区版本 (第 5 层) 和一个自适应版本,它使用最后一分钟的平均带宽来确定使用 (如§ 3.3 所述) 的分区点。我们还展示了两种版本的 JPEG - - 无带宽假设的 Progressive JPEG 和基于最近带宽历史压缩的 Baseline JPEG 的性能。
我们在合成的和真实的轨迹上查看一系列动态带宽场景的性能,以便了解 Clio 在动态环境中的性能。由于 ImageNet - 20 图像的尺寸较大,我们将其作为重点研究对象,考虑图像需要在 300ms 内处理的情况。
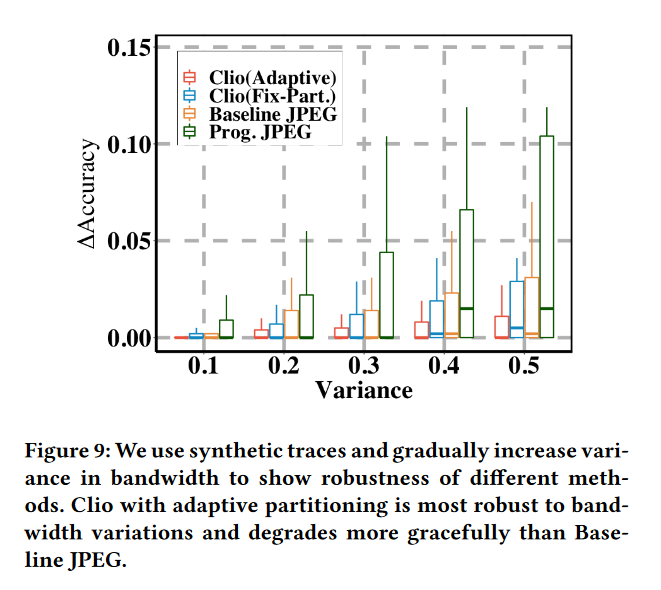
综合带宽驱动评价
图 9 显示了由于实际带宽和估计带宽之间的差异,不同方法在精度上的退化。这种差距越大,分区点或压缩比选择不当的可能性越大。
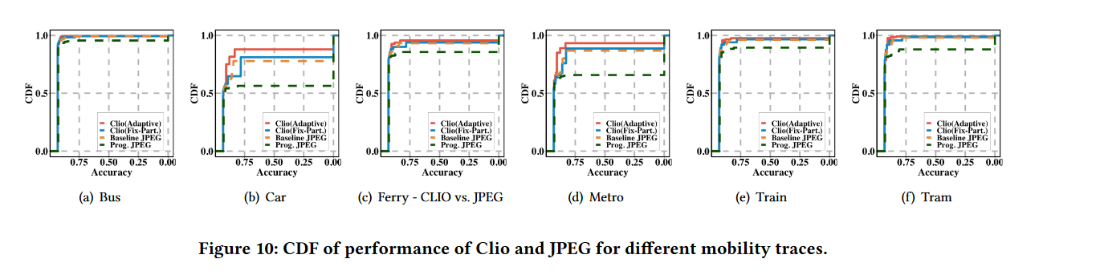
真实带宽驱动评价
具体来说,我们研究了在不同的移动环境如公共汽车、火车和渡轮中收集的 HSDPA 带宽。
结果如图 10 所示。我们注意到当带宽小于该技术使用 (例如首次扫描/切片) 生成预测结果所需的最小带宽时,我们将相应的准确率记为零。从图中可以看出,渐进切片在所有痕迹上都优于渐进 JPEG;事实上,即使不对可用带宽做任何假设,我们的方法也与 Baseline JPEG 相当。使用分区点自适应增强的 Clio 提高了性能,与基于 JPEG 的方法一样好或更好。
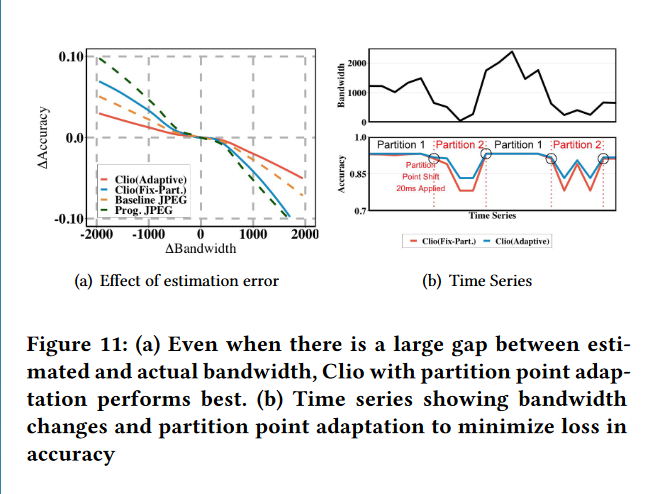
我们从两个方面对上述结果进行拓展。首先,我们从预测带宽与实际带宽不匹配的轨迹中取出所有实例,看看这对精度有什么影响。图 11 ( a ) 显示了不同方法在预测带宽和实际带宽之间不同差距的精度损失。我们看到,即使在网络动态导致的实际带宽和估计带宽之间存在巨大差距的情况下,具有自适应分区的 Clio 可以实现最好的总体精度和最小的精度退化。
其次,我们从带宽动态的轨迹中说明了使用时间序列片段的自适应分区与固定分区之间的区别。我们看到,自适应分区可以有效地适应更大的带宽变化,从而最大限度地减少由于动态带来的性能损失。
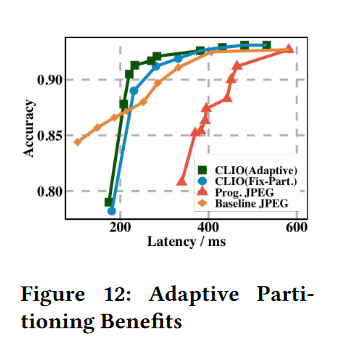
已知带宽下的性能
现在,我们对 Baseline JPEG 采取了更有利的场景,即带宽已知,并且在给定带宽的情况下优化了压缩 JPEG 的质量。
结果如图 12 所示。我们看到,选择最优的划分点可以提高分类性能,特别是在低延迟时。我们看到 Baseline JPEG 压缩明显优于 Progressive JPEG。图中还显示了 Baseline JPEG 和 Clio 之间有趣的折衷。我们看到,对于很低的延迟,Baseline JPEG 优于 Clio,因为 JPEG 计算的延迟低于 Clio 计算初始层的延迟。随着可利用的延迟增加到本地执行几个层的最低阈值以上,Clio 开始表现得更好。Clio 的渐进式版本和最优分割 + 渐进式版本的性能均优于 JPEG 版本。一旦延迟足够长以传输足够多的数据,所有方法在性能上都会收敛。
切换分区的开销
由于需要更改模型的 IoT 部分,因此更改分区点会产生一些额外的开销。假设模型存储在 GAP8 闪存上,成本只涉及模型之间的切换。在 GAP8 上,模型的权重以文件形式存储在 HyperFlash 中,需要复制到高速缓存或 HyperRAM 才能运行模型。因此,当触发分区点变化时,需要首先为当前模型释放缓存和 HyperRAM,为新模型分配新的空间。我们通过实验评估了这一过程在 GAP8 上只需要 20ms 左右,这是一个很小的开销,因为分区点 (例如, 20ms 的开销在图 11 ( b ) 中几乎看不到) 之间的切换相对不频繁)。